MySQL自定义函数和存储过程
一、介绍
MySQL函数是一些具有特定功能的方法,在编写sql时,可以进行使用,从而完成对数据的处理。
存储过程的话,更像是一些特定功能的sql组合而成的sql语句集合,由于它的事先编译,通过传入参数来执行这个过程,可以使得,在某些场景下利用存储过程的情况,达到一些快捷方便的功能。
一起来看看他们的定义和写法把。首先,加一下基础的表格
1 2 3 4 5 6 7 8 9 10 11 CREATE TABLE `tb_user` ( `id` int (11 ) NOT NULL AUTO_INCREMENT, `name` varchar (32 ) DEFAULT NULL COMMENT '姓名' , `sex` varchar (2 ) DEFAULT NULL COMMENT '性别' , `age` tinyint(4 ) DEFAULT NULL COMMENT '年龄' , `birthday` datetime DEFAULT NULL COMMENT '生日' , PRIMARY KEY (`id`) ) ENGINE= InnoDB AUTO_INCREMENT= 7 DEFAULT CHARSET= utf8mb4; INSERT INTO `tb_user`(`id`, `name`, `sex`, `age`, `birthday`) VALUES (1 , '半月无霜' , '男' , 18 , '2022-04-29 09:06:52' );
二、自定义函数
1)无参函数
1 2 3 4 5 6 7 8 9 10 11 12 drop function if exists randomNum10;create function randomNum10()returns int begin return floor (rand()* 10 ); end ;select randomNum10();
2)有参函数
1 2 3 4 5 6 7 8 9 10 11 12 drop function if exists randomNum;create function randomNum(num int )returns int begin return floor (rand()* num); end ;select randomNum(5 );
最基本的使用就是上面这样了,由于自定义函数与存储过程内,有挺多相同的东西,将在存储过程中一一介绍。
三、存储过程
语法结构
1 2 3 4 5 6 7 8 9 10 delimiter $$ create procedure 函数名([proc_parameter...]) [characteristic...] routine_body $$
上述便是存储过程的语法结构,对照上面语法结构,来简单书写一个存储过程
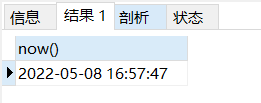
1 2 3 4 5 6 7 8 9 10 11 12 drop procedure if exists pro_test;delimiter $$ create procedure pro_test()begin select now(); end $$call pro_test();
1)变量
1.1)局部变量
局部变量,需要先定义,才能进行使用。且只能在当前的begin ... end中使用
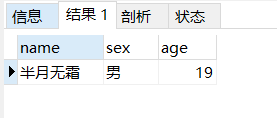
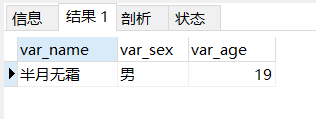
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 drop procedure if exists pro_var01;delimiter $$ create procedure pro_var01()begin declare var_name varchar (32 ) default '半月无霜' ; declare var_sex varchar (2 ); declare var_age int default 18 ; set var_age = 19 ; select sex into var_sex from tb_user where `name` = var_name; select var_name as name, var_sex as sex, var_age as age; end $$call pro_var01();
1.2)用户变量
用户变量就是用户自己定义的变量,也是在连接断开时失效。对比使用局部变量,便是不再需要提前定义
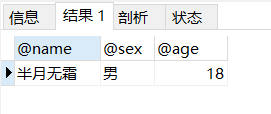
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 drop procedure if exists pro_var02;delimiter $$ create procedure pro_var02()begin set @name = '半月无霜' ; set @age = 18 ; select sex into @sex from tb_user where `name` = @name ; select @name , @sex , @age ; end $$call pro_var02();
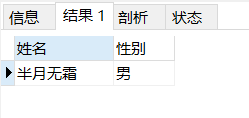
用户在同个连接中,还可以使用此变量
1 select @name as "姓名", @sex as "性别";
1.3)会话变量
如果说上面的用户变量是我们自己在一个连接中自定义的变量的话,那么会话变量就是MySQL在一个连接中初始化定义的一些变量。
在连接建立完成后,MySQL会将自己全局变量值复制一份成为当前连接的会话变量。
1 2 3 4 5 6 show session variables;select @@session .group_concat_max_len;set session group_concat_max_len = 102400 ;
在存储过程中不常用
1.4)全局变量
在上面的会话变量中,提到了全局变量。那么这个全局变量,就是MySQL服务在启动时,从配置文件中加载的一些变量,包括了一些系统的基本信息,基本配置等参数。
对比会话变量的使用,全局变量差不多
1 2 3 4 5 6 show global variables;select @@global .group_concat_max_len;set global group_concat_max_len = 102400 ;
1.5)对比
操作类型 局部变量
用户变量
会话变量
全局变量
出现的位置 函数、存储过程
命令行、函数、存储过程
命令行、函数、存储过程
命令行、函数、存储过程
定义的方式 declare count int;直接使用,@var形式
只能查看修改,不能定义
只能查看修改,不能定义
有效生命周期 begin…end一个连接内有效,当连接断开时,变量失效
一个连接内有效,当连接断开时,变量失效
服务器重启时恢复默认值
查看所有变量 /
/
show session variables; show variables;show global variables;
查看部分变量 /
/
select @@session.core_file;select @@global.core_file;
查看指定变量 select count;select @var;select @@session.core_file;select @@global.core_file;
设置指定变量 set count=1;set count:=101;select 1 into count;set @var=1;set @var:=101;select 1 into @var;set session core_file = 'ON';set global core_file = 'ON';
2)出入参
2.1)IN 入参
1 2 3 4 5 6 7 8 9 10 11 12 drop procedure if exists pro_params01;delimiter $$ create procedure pro_params01(in var_name varchar (32 ), in var_age int , in var_sex varchar (2 ))begin set var_age = var_age+ 1 ; select var_name, var_sex, var_age; end $$call pro_params01('半月无霜' , 18 , '男' );
2.2)OUT 出参
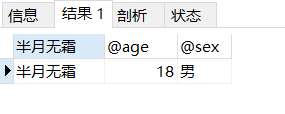
1 2 3 4 5 6 7 8 9 10 11 12 13 14 drop procedure if exists pro_params02;delimiter $$ create procedure pro_params02(in var_name varchar (32 ), out out_age int , out out_sex varchar (2 ))begin select age, sex into out_age, out_sex from tb_user where name = var_name; end $$call pro_params02('半月无霜' , @age , @sex );select '半月无霜' , @age , @sex ;
2.3)INOUT 出入参
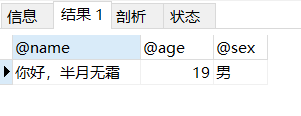
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 drop procedure if exists pro_params03;delimiter $$ create procedure pro_params03(inout var_name varchar (32 ), inout var_age int , inout var_sex varchar (2 ))begin declare var_temp varchar (32 ) default var_name; set var_name = concat('你好,' , var_name); set var_age = var_age + 1 ; select sex into var_sex from tb_user where name = var_temp; end $$set @name = '半月无霜' ;set @age = 18 ;set @sex = '未知' ;call pro_params03(@name , @age , @sex );select @name , @age , @sex ;
3)判断语句
使用if...then...else...end if来进行,使用的语法格式如下
1 2 3 4 if 判断语句 then 处理内容 [elseif 判断语句 then 处理内容] ... [else 处理内容] end if
在过程中的具体使用
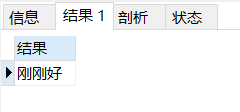
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 drop procedure if exists pro_judge01;delimiter $$ create procedure pro_judge01(in var_score int , out var_result varchar (4 ))begin if var_score > 60 then set var_result = '合格' ; elseif var_score = 60 then set var_result = '刚刚好' ; else set var_result = '不合格' ; end if; select var_result as "结果"; end $$call pro_judge01(60 , @result );
4)循环语句
循环基本上是有三种标准的写法,看自己喜欢用哪一种吧
4.1)WHILE
while语句语法
1 2 3 while 判断语句 do 循环体 end while;
在过程中的具体使用
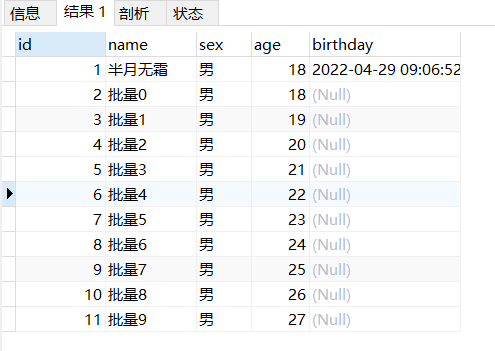
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 drop procedure if exists pro_cyclic01;delimiter $$ create procedure pro_cyclic01()begin declare var_i int default 0 ; while var_i < 10 do INSERT INTO `tb_user`(`name`, `sex`, `age`) VALUES (concat('批量' , var_i), '男' , 18 + var_i); set var_i = var_i+ 1 ; end while; end $$call pro_cyclic01();select * from tb_user;
4.2)REPEAT
第二种循环写法写法,其中判断语句有所不同,为真才会退出。
1 2 3 4 repeat 循环体 until 判断语句 end repeat;
在过程中的具体使用
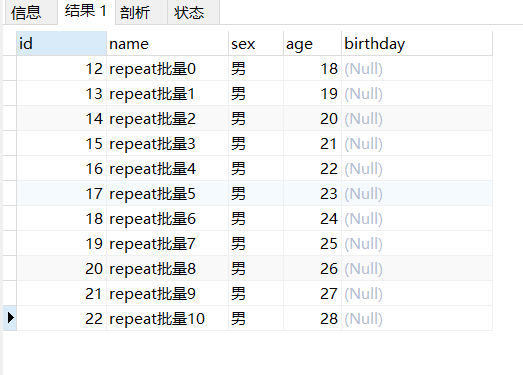
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 drop procedure if exists pro_cyclic02;delimiter $$ create procedure pro_cyclic02()begin declare var_i int default 0 ; repeat INSERT INTO `tb_user`(`name`, `sex`, `age`) VALUES (concat('repeat批量' , var_i), '男' , 18 + var_i); set var_i = var_i+ 1 ; until var_i > 10 end repeat; end $$call pro_cyclic02();select * from tb_user where name like 'repeat%' ;
4.3)LOOP
loop循环,语法如下
1 2 3 4 5 6 标签:loop 循环体 if 判断语句 then leave 标签; end if; end loop;
在过程中的具体使用
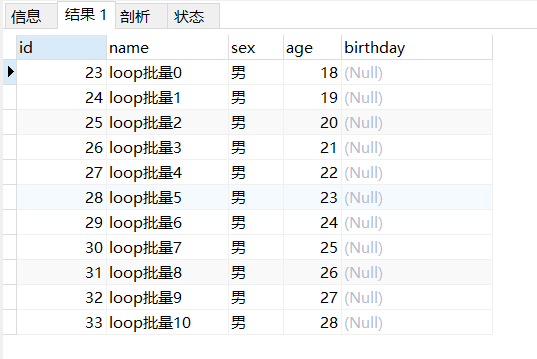
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 drop procedure if exists pro_cyclic03;delimiter $$ create procedure pro_cyclic03()begin declare var_i int default 0 ; loop_label:loop INSERT INTO `tb_user`(`name`, `sex`, `age`) VALUES (concat('loop批量' , var_i), '男' , 18 + var_i); set var_i = var_i+ 1 ; if var_i > 10 then leave loop_label; end if; end loop; end $$call pro_cyclic03();select * from tb_user where name like 'loop%' ;
5)游标
在上面的循环中,好像只是简单的次数循环。那如果需要对查询的结果集进行循环的话,上面的循环方法就无能为力了。
这时候我们就得使用到游标,来对查询结果集进行遍历。
简单来看看这个需求,现在我们有一张计划表tb_user_plan,我们将遍历这张表,根据里面定义的计划向tb_user中插入数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 CREATE TABLE `tb_user_plan` ( `id` int (11 ) NOT NULL AUTO_INCREMENT, `name` varchar (32 ) DEFAULT NULL COMMENT '姓名' , `sex` tinyint(4 ) DEFAULT NULL COMMENT '性别,1=男,2=女' , `age` int (11 ) DEFAULT NULL COMMENT '年龄' , `count` int (11 ) DEFAULT NULL COMMENT '数量' , PRIMARY KEY (`id`) ) ENGINE= InnoDB AUTO_INCREMENT= 6 DEFAULT CHARSET= utf8mb4; INSERT INTO `tb_user_plan`(`id`, `name`, `sex`, `age`, `count`) VALUES (1 , '遍历1' , 1 , 18 , 4 );INSERT INTO `tb_user_plan`(`id`, `name`, `sex`, `age`, `count`) VALUES (2 , '遍历2' , 1 , 18 , 4 );INSERT INTO `tb_user_plan`(`id`, `name`, `sex`, `age`, `count`) VALUES (3 , '遍历3' , 1 , 19 , 4 );INSERT INTO `tb_user_plan`(`id`, `name`, `sex`, `age`, `count`) VALUES (4 , '遍历4' , 2 , 18 , 4 );INSERT INTO `tb_user_plan`(`id`, `name`, `sex`, `age`, `count`) VALUES (5 , '遍历5' , 2 , 18 , 4 );
那么过程的实现如下
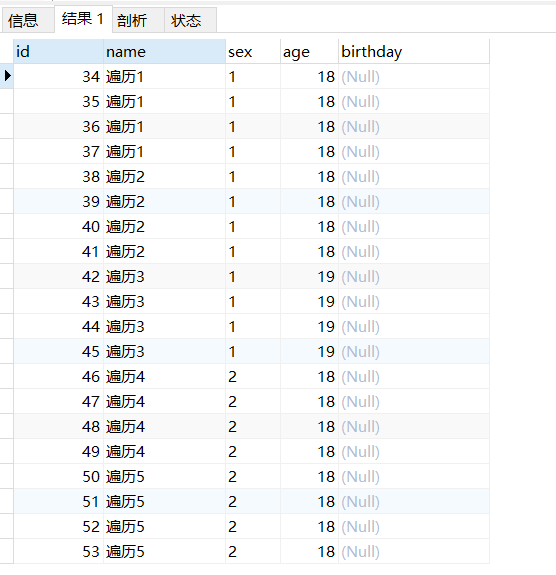
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 drop procedure if exists pro_cursor;delimiter $$ create procedure pro_cursor()begin declare var_i int ; declare var_name varchar (32 ); declare var_sex tinyint; declare var_age int ; declare var_count int ; declare done int default 0 ; declare my_cursor cursor for select name, sex, age, count from tb_user_plan; declare continue handler for not found set done = 1 ; open my_cursor; my_label:loop fetch my_cursor into var_name, var_sex, var_age, var_count; if done= 1 then leave my_label; end if; set var_i = 0 ; while var_i< var_count do INSERT INTO `tb_user`(`name`, `sex`, `age`) VALUES (var_name, var_sex, var_age); set var_i = var_i+ 1 ; end while; end loop my_label; close my_cursor; end $$call pro_cursor();select * from tb_user where name like '遍历%' ;
在使用上的流程简单说就是
定义游标
打开游标
遍历游标,使用loop方式
如果游标遍历完成,使用leave方式离开循环
业务,过程体
循环结束,与步骤3行成闭环
关闭游标,与步骤2行成闭环
6)异常
在存储过程运行的过程中,程序会发生一些有一定可能会出现的异常,如果不对这些异常进行处理,会导致我们的存储过程运行失败。所以对应Java中的try...catch...,存储过程也有一套自己的异常捕获处理方式。
在上面的定义游标时,应该有发现了,我们额外定义了一个continue handler,如下
1 declare continue handler for not found set done = 1 ;
这就要和我们要讲得异常处理有关,上面这个只是其中之一。实际上有三个概念,分别如下
condition
handler
diagnostics area
6.1)CONDITION
存储过程中出现的异常被称为condition,就像java中的Exception一样。
我们可以定义一个condition,MySQL官方说的,定义语法结构如下
1 2 3 4 5 6 DECLARE condition_name CONDITION FOR condition_valuecondition_value: { mysql_error_code | SQLSTATE [VALUE ] sqlstate_value }
这段语句声明了一个错误条件,将名称与需要特定处理的条件相关联。此处定义的condition将会在后续被handler进行处理。
很多人不清楚condition_value是什么,上面官方语法结构已经说了,分别可以是mysql_error_code、``
mysql_error_code:表示 MySQL 错误代码的整数文字,查看官网 有哪些错误代码
不要使用 MySQL 错误代码 0,因为这表示成功而不是错误条件
SQLSTATE [VALUE] sqlstate_value:一个 5 字符的字符串文字,指示 SQLSTATE 值,查看官网 有哪些错误代码
不要使用以 开头的 SQLSTATE 值, '00’因为它们表示成功而不是错误情况
使用mysql_error_code声明condition
1 2 3 4 5 DECLARE no_such_table CONDITION FOR 1051 ;DECLARE CONTINUE HANDLER FOR no_such_tableBEGIN END ;
使用SQLSTATE值声明condition
1 2 3 4 5 DECLARE no_such_table CONDITION FOR SQLSTATE '42S02' ;DECLARE CONTINUE HANDLER FOR no_such_tableBEGIN END ;
在官网的错误代码列表可以搜到,1051和 42s02指的是没有找到表
6.2)HANDLER
在上面已经两次提到了handler,大家应该知道了它的作用了吧。这个handler是用来处理condition的,当condition发生时,就会执行handler中的处理逻辑。
官网的文档,语法结构图如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 DECLARE handler_action HANDLER FOR condition_value [, condition_value] ... statement handler_action: { CONTINUE | EXIT | UNDO } condition_value: { mysql_error_code | SQLSTATE [VALUE ] sqlstate_value | condition_name | SQLWARNING | NOT FOUND | SQLEXCEPTION }
通过语法结构来看,我们可以发现这些信息
一个handler,可以处理多个condition
我们可以不再定义condition,因为handler中可以直接使用mysql_error_code和SQLSTATE
处理逻辑一共有三种
CONTINUE:继续执行
EXIT:退出
UNDO:目前还不支持
其中condition_value还支持其他三种类型的,分别是
SQLWARNING:统称,以01为开头的SQLSTATE集合
NOT FOUND:统称,以02为开头的SQLSTATE集合
SQLEXCEPTION:不以00、01或02开头的SQLSTATE值
语法定义就是这样,我们来看官网上 的这个例子
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 mysql> CREATE TABLE test.t (s1 INT , PRIMARY KEY (s1)); Query OK, 0 rows affected (0.00 sec) mysql> delimiter / / mysql> CREATE PROCEDURE handlerdemo () BEGIN DECLARE CONTINUE HANDLER FOR SQLSTATE '23000' SET @x2 = 1 ; SET @x = 1 ; INSERT INTO test.t VALUES (1 ); SET @x = 2 ; INSERT INTO test.t VALUES (1 ); SET @x = 3 ; END ; / / Query OK, 0 rows affected (0.00 sec) mysql> CALL handlerdemo()/ / Query OK, 0 rows affected (0.00 sec) mysql> SELECT @x / / + | @x | + | 3 | + 1 row in set (0.00 sec)
简单的说,就是一张表,重复插入,导致主键冲突的condition,这边handler的处理是继续执行。
所以当12行报错时,13行依旧会进行执行,所以最后的答案就是3
当我们要忽略某个condition时,请为其声明一个condition 处理程序并将其与一个空块相关联,begin...end,如下
1 DECLARE CONTINUE HANDLER FOR SQLWARNING BEGIN END ;
在使用循环时,需要注意块标签的范围不包括在块中声明的处理程序的代码 ,听着有点拗口,我们直接看官方的例子
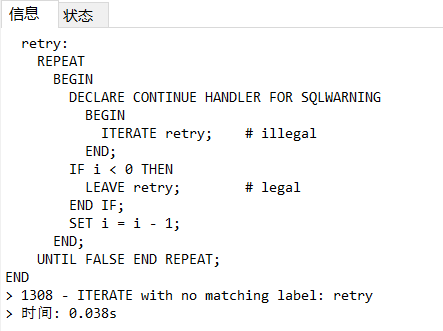
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 CREATE PROCEDURE p ()BEGIN DECLARE i INT DEFAULT 3 ; retry: REPEAT BEGIN DECLARE CONTINUE HANDLER FOR SQLWARNING BEGIN ITERATE retry; # illegal END ; IF i < 0 THEN LEAVE retry; # legal END IF; SET i = i - 1 ; END ; UNTIL FALSE END REPEAT; END ;
在程序执行时,会报出下面这个异常
这是因为,retry标签在 if块内的语句的范围内 。它不在handler处理程序的范围内,因此那里的引用无效并导致错误。
简单的来说,就是handler不能使用leave或者iterate操控外部的循环。
所以,如果爆出异常,我们要退出时,可以这样
1 DECLARE EXIT HANDLER FOR SQLWARNING BEGIN END ;
如果我们还需要做一些处理的话,我们可以这样
1 2 3 4 DECLARE EXIT HANDLER FOR SQLWARNING BEGIN block cleanup statements END ;
当然,我们也可以定义一个临时变量,当做状态。就像上面游标的处理方式一样,具体如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 CREATE PROCEDURE p ()BEGIN DECLARE i INT DEFAULT 3 ; DECLARE done INT DEFAULT FALSE ; retry: REPEAT BEGIN DECLARE CONTINUE HANDLER FOR SQLWARNING BEGIN SET done = TRUE ; END ; IF done OR i < 0 THEN LEAVE retry; END IF; SET i = i - 1 ; END ; UNTIL FALSE END REPEAT; END ;
爆出异常后,修改状态值,后续的程序后判断这个状态,来进行leave或者iterate
6.3)Diagnostics Area
Diagnostics Area是诊断区域,查看官方文档 。
感觉有点用不到,暂时先不做记录了
四、最后
存储过程以前就在用,但也是和平常懒人一下,用到的时候导出翻博客,没有记录自己的笔记。
这很不好,正好趁这次把存储过程过了一遍,问题不大。
本文写得不是很深,如果有什么新的注意点,我会在此进行更新的。
我是半月,祝你幸福!!!